
毎日見たいアニメやドラマを探して、最新話をダウンロードする日課がありますでしょうか。
一日数回チェックすることもあるし、最新話は何話かを確認しないと行けないし、時々見落とすこともあります。
この日課から開放し、機械に任せて自動的にダウンロードすることを実現しました。
この記事は自分作ったプログラムを公開し、解析します。それをベースに誰でも自分用のダウンロードプログラムを作ることをできます。
●プログラムの特徴
●プログラム公開
●自分用のカスタマイズ方法
プログラムの特徴
このプログラムができることは:
1時間毎に自動起動し、指定のサイトから指定のキーワードで最新話のTorrentファイルをダウンロードします。
BTソフト(uTorrent)がフォルダを監視し、Torrentファイルがあれば、自動ダウンロードします。Torrentファイルを自動削除します。
プログラム公開
早速、プログラムを公開します。
プログラム内容
download_rss.py:
import os, time, requests, urllib, re
from bs4 import BeautifulSoup
target_url = 'https://share.dmhy.org/topics/list/sort_id/2'
# 保存先フォルダ
save_dir = 'c:\\WorkSpace\\Chrome\\'
html = requests.get(target_url).text
soup = BeautifulSoup(html, 'html5lib')
# ダウンロードのメイン処理
def download_torrents():
html = requests.get(target_url).text
# 解析してURLの一覧を取得
urls = get_torrent_urls(html)
# URLの一覧をダウンロード
go_download(urls)
# listに合致かを判断
def contents_confirm(content):
with open(r'c:\WorkSpace\publicTools\scraping\pattern.txt', encoding='utf8') as f:
text = f.read().strip()
lines = text.split("\n")
for row in lines:
# print(row)
result = re.match(row, content)
# print(result)
if result:
return True
return False
# HTMLからURL一覧を取得
def get_torrent_urls(html):
# HTMLを解析
soup = BeautifulSoup(html, 'html5lib')
res = []
for link in soup.select('#topic_list > tbody > tr > td.title > a'):
text = link.getText()
# print(text)
if(contents_confirm(text.strip())):
subLink = link.get('href')
# URLを絶対パスに変換
url = urllib.parse.urljoin(target_url, subLink)
print(url)
# URLからHTML解析し、TorrentのURL取得
subhtml = requests.get(url).text
subsoup = BeautifulSoup(subhtml, 'html5lib')
torrentUrltmp = subsoup.select_one('#tabs-1 > p:nth-child(1) > a')
torrentUrl = urllib.parse.urljoin(target_url, torrentUrltmp.get('href'))
print(torrentUrl)
res.append(torrentUrl)
return res
# 連続でURL一覧をダウンロード
def go_download(urls):
if not os.path.exists(save_dir):
os.mkdir(save_dir)
for url in urls:
fname = os.path.basename(url)
save_file = save_dir + '/' + fname
r = requests.get(url)
with open(save_file, 'wb') as fp:
fp.write(r.content)
print("save:", save_file)
time.sleep(1) # 重要
if __name__ == '__main__':
download_torrents()
pattern.txt:
.*[NC-Raws] 轉生成蜘蛛又怎樣!(僅限港澳台地區).*1080p.*
.*c.c動漫.*Boruto -Naruto Next Generations.*
.*DMHY.*Black_Clover.*
.*Skymoon-Raws.*One Piece.*正式版本.*
.*NC-Raws.*關於我轉生變成史萊姆這檔事 第二季(僅限台灣地區).*
.*NC-Raws.*記錄的地平線 圓桌崩壞(僅限港澳台地區).*
.*NC-Raws.*進擊的巨人 The Final Season(僅限港澳台地區).*最新のソースはGitHubからダウンロードできます。
解説
使っている技術:Python、スクラピング(BeautifulSoup)、正規表現
target_urlでダウンロードするサイトを指定。
pattern.txtに見たいアニメのキーワードを正規表現で定義、このファイルを都度更新します。
Pythonの基礎やスクラピングの技術を解説しませんが、知りたい方は下記の本をご参考ください。自分がこの本をきっかけにこのプログラム作りました。
シゴトがはかどる Python自動処理の教科書
Winタスクスケジューラ登録
1時間毎に自動実行するには、タスクスケジューラに登録する必要で、Win10の登録方法を紹介します。
タスクスケジューラ起動
タスクスケジューラ設定
タスク作成:
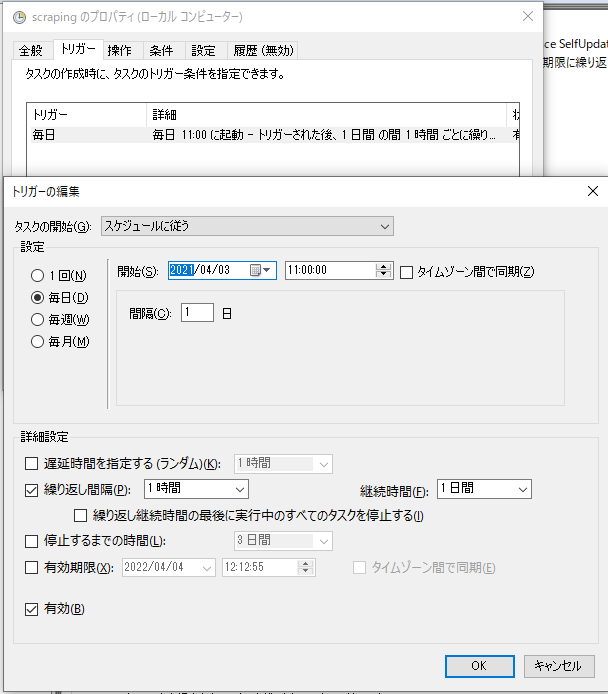
トリガー設定:1時間毎に実行
起動プログラムを指定:
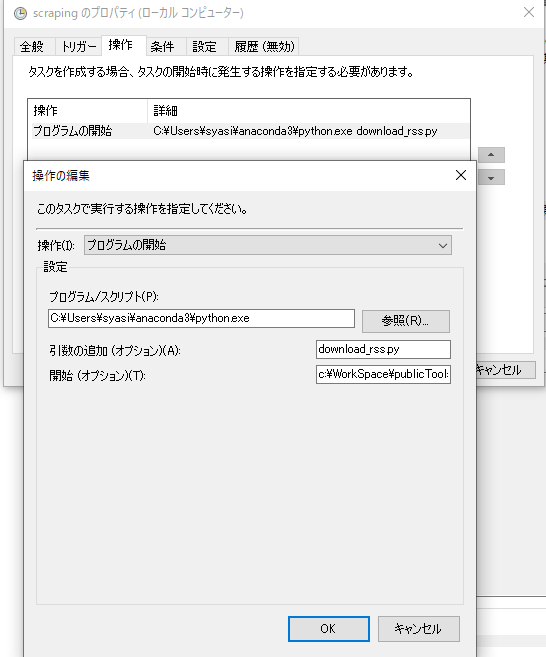
プログラム/スクリプト:C:\Users\syasi\anaconda3\python.exe ※Python実行パス
引数の追加:download_rss.py ※Pythonファイル名
開始:c:\WorkSpace\publicTools\scraping\ ※Pythonファイルのパス
BTソフトの設定
utorrent2.2.1の自動化設定方法を紹介します。
最新バージョンは広告がうるさいのため、安定した2.2.1を使用しています。
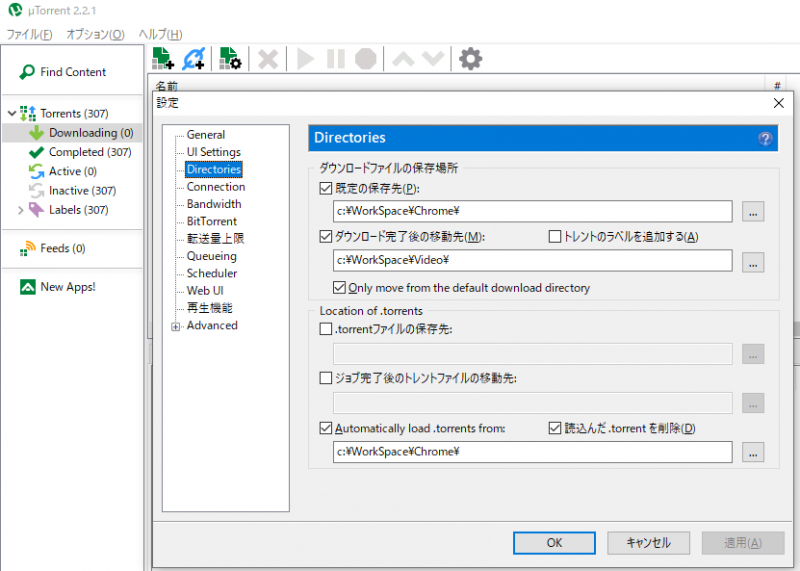
監視したフォルダを指定すればOKです。後utorrentをバックで起動すればOKです。
自分用のカスタマイズ方法
環境準備
Pythonの環境はAnaconda利用しています。
コードの編集はVSCode利用しています。
注意点:VscodeでPython実行するとき、環境変数にPath指定しないとSSLErrorになります。
Win10の環境変数方法:
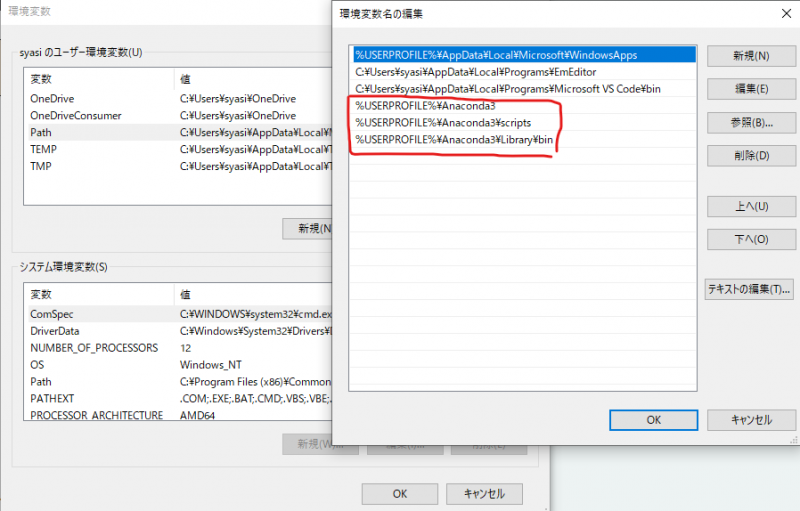
自分のPathに赤枠の設定を追加してください。
%USERPROFILE%\Anaconda3
%USERPROFILE%\Anaconda3\scripts
%USERPROFILE%\Anaconda3\Library\binselect内容を調査方法
ChromeのF12で開発モードを開き
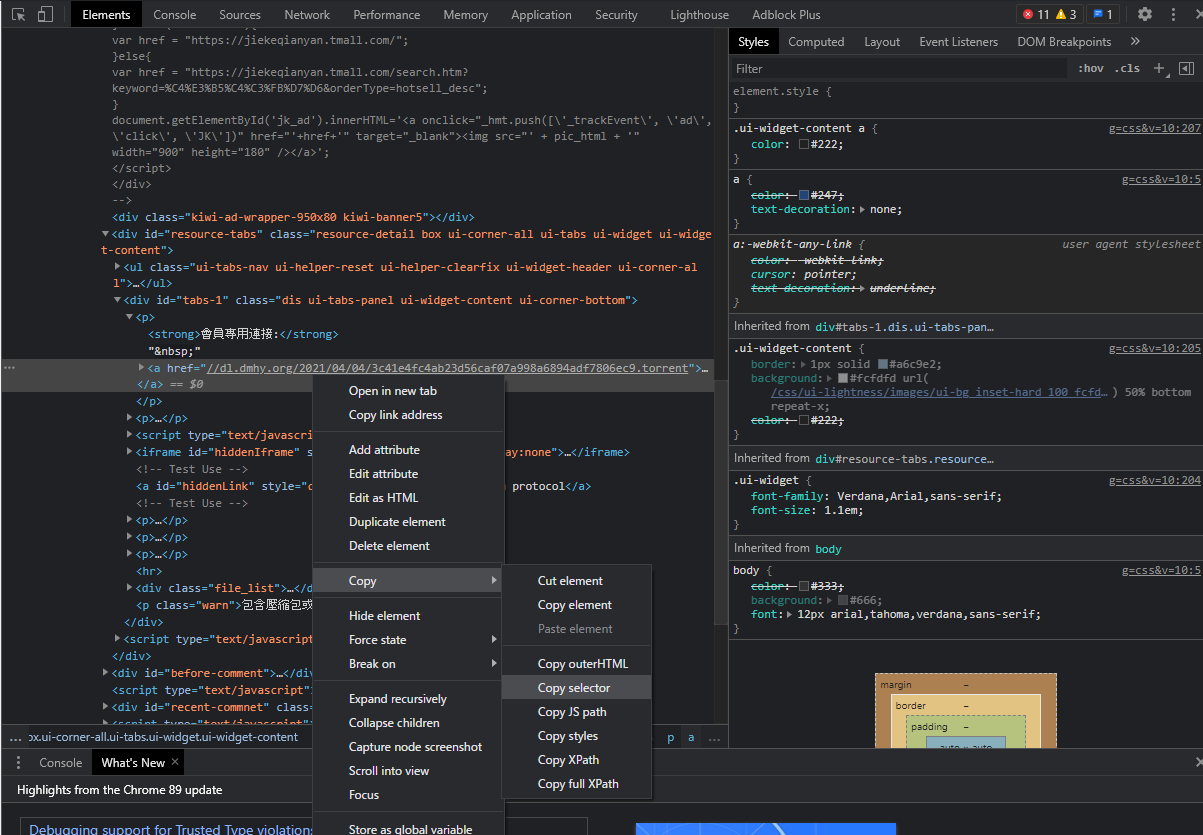
Copy selectorを選択すれば、下記のように該当箇所の位置をわかります。かなり便利です。
#tabs-1 > p:nth-child(1) > aまとめ
すべての人は1日24時間しかありません。日々やっていることを短縮できるか、無駄がないか、自動化できるかをずっと考えています。
役に立ったら嬉しいです。不明点があればコメント下さい。


コメント